Kas ir datu bāzes?
Iedomāsimies, ka mums ir jāsaglabā informācija par visiem skolas skolēniem. Tam mēs varam izmantot Excel tabulu, taču informācija nebūs pārskatāma, orientēties tajā būs grūti un vajadzīgo datu atrašana aizņems daudz laika.
Tāpēc izmanto datu bāzes, kur dati glabājas strikti noteiktā formā, tie izkārtoti vairākās tabulās un to apstrādei izmanto īpašas komandas.
Datu bāzes pamatelements ir tabula.
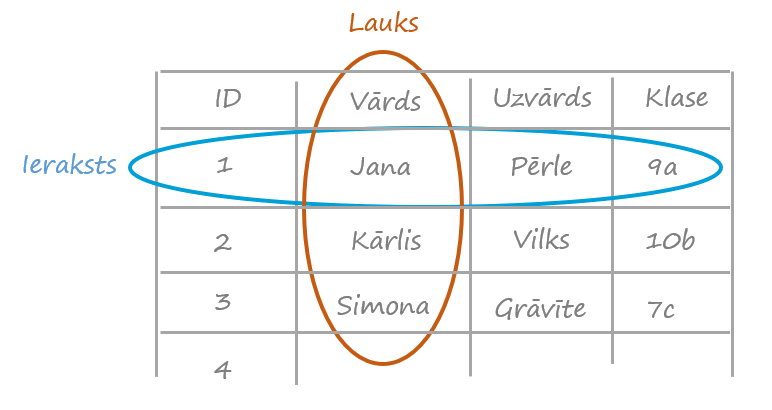
Attēlā redzam, ka kolonnu sauc par lauku, bet rindu par ierakstu.
ID lauks šajā gadījumā ir tā sauktais primārās atslēgas lauks. Ja 9.a klasē mācās divas Janas Pērles, tad ID katrā gadījumā būs atšķirīgs. Tas palīdz unikāli identificēt ierakstus tabulā.
Primārā atslēga ir obligāts lauks, kas unikāli identificē ierakstu.
Termini
| Termins | Skaidrojums |
|---|---|
| Datu bāze | Saistītu datu kopums, kas nodrošina datu uzglabāšanu, atlasi un kārtošanu |
| Primārā atslēga | Tabulas lauks, kas unikāli identificē katru ierakstu |
| Relācija | Saite starp tabulām |
| Vaicājums | Paņēmiens, ko izmanto, lai atlasītu datus no tabulas |
| Forma | Datu ievades konteineris, kas iekļauj teksta laukus, pogas, izvēles rūtiņas u.c. elementus |
| Transakcija | Viena vai vairākas secīgas nepārtrauktas operācijas datu bāzē |
Vienkāršās datu bāzēs kā ID izmanto automātisku numerāciju.
SQL komandas
Šī sadaļa apraksta vairākas komandas, kuras ir sastopamas SQL datubāzēs.
SQL vaicājumu izpildes secība
SQL datu bāzes nepilda vaicājumus no labi pa kreisi. Tās pilda vaicājumus pēc šīs secības:
- FROM/JOIN
- WHERE
- GROUP BY
- HAVING
- SELECT
- ORDER BY
- LIMIT/OFFSET
Tātad, sekojošā vaicājuma sākumā datu bāze apskatās no kuras tabulas datus ņemt pēc FROM atslēgas vārda.
SELECT
vards, epasts
FROM
pirceji
WHERE
konta_statuss = "deaktivizets"
ORDER BY
vards, id
LIMIT 10Tad datu bāze apskatās filtrus pēc WHERE atslēgas vārda (šajā gadījumā, vai konta statuss ir deaktivizēts).
Tad datu bāze izvēlas nepieciešamās atgriežamās kolonas pēc SELECT atslēgas vārda.
Pēctam datu bāze sakārto datus pēc ORDER BY atslēgas vārdiem un pašās beigās viņa saīsina rezultātu uz tikai 10 ierakstiem.
Svarīgi!
Rakstot SQL vaicājumus, tāpat kā parastu kodu, ir ļoti svarīgi saprast kādā secībā tas izpildās. Nezinot vaicājumu izpildes secību, jūs varat uzrakstīt vaicājumu kurš vai nu neatgriež pareizos datus, vai arī vaicājumu kurš nav tik optimizēts kā jums šķiet.
Explain
Svarīgi!
Šī komanda ir priekš MySQL, PostgreSQL un SQLite
Īsumā: EXPLAIN izskaidro cik daudz rindas tiek lasītas u.tml. bez vaicājuma veikšanas, jeb tikai ar statistiku. EXPLAIN ANALYZE dara to pašu, bet veic vaicājumu.
Ja mums ir problēmas ar veiktspēju, mēs varam izmantot EXPLAIN komandu, lai to analizētu.
Komanda EXPLAIN [vaicājums] ar analītiku izskaidro kas notiek ar to vaicājumu. Tas nepalaiž vaicājumu, tas izmanto tikai iepriekš zināmo analītiku, lai to aprakstītu. Tas ir labi tad, ja gribi ātri dabūt vispārīgu info par to, kas notiek ar to vaicājumu neiedodot papildus slodzu datu bāzei.
EXPLAIN SELECT * FROM people WHERE birthday BETWEEN '1988-01-01' AND '1988-01-31';
EXPLAIN ANALYZE
Komanda EXPLAIN ANALYZE [vaicājums] atšķiras ar to, ka šī komanda veic vaicājumu, nevis izmanto statistiku. Tas nozīmē, ka šī komanda ir precīza, bet ļoti dārga resursu ziņā.
EXPLAIN ANALYZE SELECT * FROM people WHERE birthday BETWEEN '1988-01-01' AND '1988-01-31';
Datu tipi
Ja apskatām skolēnu datu bāzi, tajā var glabāties gan vārds un uzvārds, kas ir teksts, gan dzimšanas dati, kas ir datums, kā arī vecums, kas pēc būtības ir skaitlis.
Tāpēc izšķir vairākus datu tipus, kas nosaka formu, kādā dati glabāsies tabulas laukā.
Dažādās datu bāzu sistēmās datu tipi var atšķirties, bet apskatīsim izplatītākos.
| Datu tips | Apraksts | Piemērs |
|---|---|---|
| integer (int) | Skaitlis | 4 |
| real (float) | Decimālskaitlis | 5.6 |
| text | Teksts | Anna |
| date/time | Datums un laiks | 04.06.2020 |
| null | Tukšā vērtība | NULL |
Telefona numurs, kā arī personas kods ir teksts, jo var saturēt zīmes, kas nav cipari, piemēram, + vai -
Datu bāzu sistēmas
Lai izveidotu datu bāzi, izmanto tā sauktās datu bāzu vadības (pārvaldības) sistēmas.
Tās iedalās divos veidos:
- SQL (relācijtabulu datu bāzes)
- NO-SQL (bezrelācijtabulu datu bāzes)
SQL sistēmas datu strikti glabā ar relācijām sasaistītās tabulās, savukārt, NO-SQL sistēmas datus glabā nesaistītā veidā, piemēram, JSON vai CSV failā.
Ar SQL parasti saprot valodu, kas ietver speciālas komandas darbam ar datu bāzēm. Gluži kā latviešu valodai, arī SQL ir daudz un dažādi dialekti, piemēram, SQLite, MySQL, PostgreSQL. Tie visi paredzēti vienam mērķim, tomēr ir nedaudz atšķirīgi.
Pastāv arī grafiskās sistēmas, piemēram, Microsoft Access vai dBase, kas ļauj grafiski veidot tabulas un relācijas, bet pamatā izmanto kādu no SQL dialektiem.
Kārtošana
Ja mēs strādājam ar datubāzēm mums ir vairāki paņēmieni kā sakārtot datus.
Deterministiska sakārtošana
Šis kārtošanas paņēmiens ir vislabākais,jo nepieciešams, lai dati vispār nekad nemaina vietu.
Īsumā: kārtojot pēc 1 kolonas un id rezultāti vienmēr būs tajā pašā vietā
1 kolona
Mums ir datu bāze un mēs kārtojam pēc kolonas first_name:
| id | first_name | last_name | birthday |
|---|---|---|---|
| 2 | Aaron | Francis | 1988-02-14 |
| 589 | Aaron | Streich | 1982-06-29 |
| 13704 | Aaron | Braun | 1974-12-10 |
| 8441 | Aaron | Kreiger | 1997-01-27 |
| 9179 | Aaron | Wolf | 1985-06-04 |
| 10970 | Aaron | Reichert | 1998-11-03 |
| 13082 | Aaron | Collier | 1980-10-26 |
| 3896 | Aaron | Corkery | 1979-06-04 |
| 19399 | Aaron | Watsica | 2001-10-21 |
| 25995 | Aaron | Runte | 1979-01-02 |
Kā mēs redzam, ir ļoti daudz ieraksti uz vārda "Aaron", un ar katru vaicājumi tie dati mainīs vietu. Tā nav deterministiska sakārtošana.
2 kolonas
Ar vienu kolonu nepietiek, jo tajā ierakstu vērtība var atkārtoties. Tad kā būtu ar first_name, last_name?
| id | first_name | last_name | birthday |
|---|---|---|---|
| 2 | Aaron | Abbott | 1988-02-14 |
| 589 | Aaron | Anderson | 1982-06-29 |
| 13704 | Aaron | Anderson | 1974-12-10 |
| 8441 | Aaron | Auer | 1997-01-27 |
| 9179 | Aaron | Auer | 1985-06-04 |
| 10970 | Aaron | Bahringer | 1998-11-03 |
| 13082 | Aaron | Bailey | 1980-10-26 |
| 3896 | Aaron | Balistreri | 1979-06-04 |
| 19399 | Aaron | Balistreri | 2001-10-21 |
| 25995 | Aaron | Barrows | 1979-01-02 |
Arī šis nederēs, jo ierakstiem 589 un 13704 ir tas pats uzvārds, un dēļ tā ar katru vaicājumu viņi var mainīties vietām!
3 kolonas
Ar vienu kolonu nepietiek, ar divām nepietiek, tad nu jāpaņem ar 3 (vai pat vairāk)!
... bet tā arī nevar būt patiesa deterministiska kārtošana, jo lai gan tas būtu ļoti reti, var sakrist 2 (vai vairāk) ieraksti ar tādiem pašiem datiem pat 3 vai vairāk kolonās
1 kolona un id
Un tagad mēs beidzot nonākam pie pareizā risinājuma. Pieliekot id pie kārtojamās kolonas mēs varam pārliecināties ka tā tiešām būs deterministiskā kārtošana jo id nekad neatkārtosies.
SQL vaicājums priekš šī paņēmiena izskatīsies šādi:
select
*
from
people
order by
first_name, idRelācijas un ER modelis
Lai datu bāzes tabulā vairākkārt nedublētos dati, tos izdala pa vairākām tabulām, piemēram, skoleni, klases, skolotaji vai līdzīgi. Noliktavas uzraudzības datu bāzē tās varētu būt preces, noliktavas_zales, parvaldnieki.
Vairāku tabulu gadījumā tās vienmēr tiek sasaistītas. Tam izmanto saites jeb relācijas.
Relācija ir saite starp divām datu bāzes tabulām.
Relāciju veidi
Relācijām izšķir 3 galvenos tipus:
- viens-pret-vienu (viens ieraksts no A tabulas atbilst vienam ierakstam no B tabulas)
- viens-pret-daudziem (viens ieraksts no A tabulas atbilst vairākiem ierakstiem no B tabulas)
- daudzi-pret-daudziem (vairāki ieraksti no A tabulas atbilst vairākiem ierakstiem no B tabulas)
Vidusskolas programmēšanas padziļinātā eksāmenā tiek lietoti šādi apzīmējumi tabulu relāciju pierakstam:

Avots: https://mape.gov.lv/api/files/C04D96D4-F361-4572-8375-2C36B798A81C/download
Daudzi-pret-daudziem relācijas gadījumā izmanto papildus tabulu un divas viens-pret-daudziem relācijas.
Piemērs - skolēni un klases, audzinātāji
Relāciju zīmējumos tiek izmantota Sqlite datu lauku veidi.
Attēlā redzamas tabulas skoleni un klases. Tā kā vienā klasē var būt vairāki skolēni, bet skolēns var būt tikai vienā klasē, tā ir viens-pret-daudziem relācija.
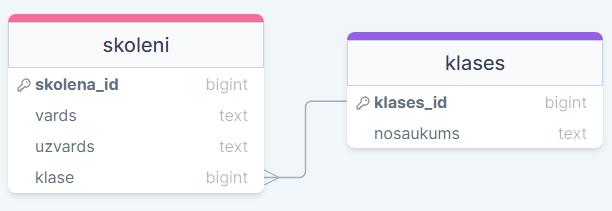
Šajā piemērā klase un klases_id ir saistītie lauki.
Saistītajiem laukiem svarīgi iestatīt vienādu datu tipu!
Papildināsim piemēru ar tabulu audzinataji.
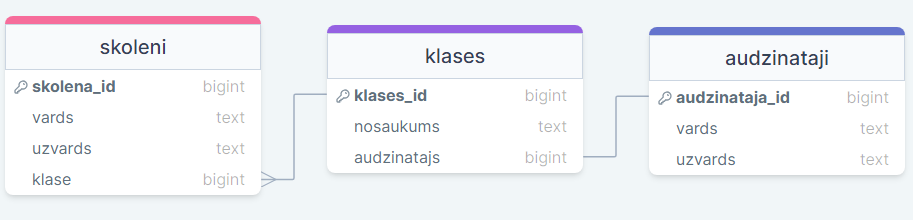
Zinot, ka katrai klasei var būt tikai viens audzinātājs un katram audzinātājam var būt tikai viena klase, tā ir viens-pret-vienu relācija.
Var būt piemērs, kad klasei ir vairāki audzinātāji. Tad iespējams izmantot vēl vienu tabulu, kurā glabā relācijas starp klasi un audzinātāju.
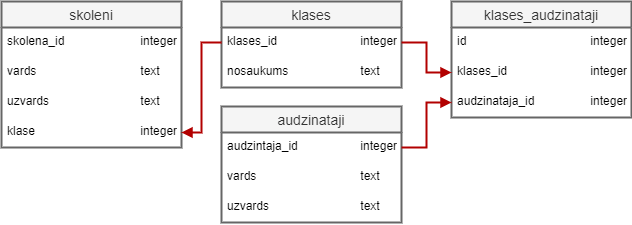
Šajā piemērā, datubāzē ir 3 tabulas: klases, audzinataji un klases_audzinataji.
Tabulā klases_audzinataji ir divi lauki, kas saista tabulas klases un audzinataji.
Tiek izmantota arī relācija viens-pret-vienu tabulā klases_audzinataji pret tabulu audzinataji.
Piemērs - skolēnu vērtējumu datubāze
Vēl viens piemērs ar skolēnu datubāzi. Dots ER modelis.
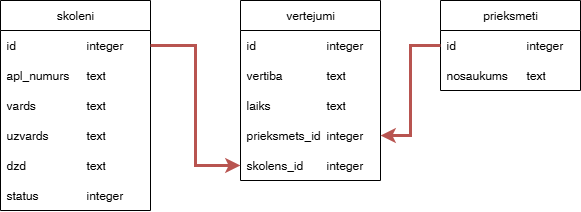
Dotas trīs datubāzes tabulas: skoleni, vertejumi un prieksmeti.
Tabulā skoleni ir informācija par skolēniem.
Tabulā prieksmeti ir informācija par mācību priekšmetiem.
Tabulā vertejumi ir informācija par skolēnu vērtējumiem mācību priekšmetos.
Tabulu apraksti:
skoleni tabulā ir lauki:
id(primārā atslēga);vards- skolēna vārds;uzvards- skolēna uzvārds;apl_numurs- skolēna apliecības numurs;dzd- skolēna dzimšanas datums, paredzēts formāts yyyy-mm-dd;status- skolēna statuss (aktīvs/neaktīvs);
id(primārā atslēga);nosaukums- mācību priekšmeta nosaukums;
id(primārā atslēga);skolens_id(ārējā atslēga uz tabulu skoleni);prieksmets_id(ārējā atslēga uz tabulu prieksmeti);vertiba- skolēna vērtējums mācību priekšmetā, paredzēts skaitlis no 1 līdz 10 un "nv" - nav vērtējuma;laiks- vērtējuma izveidošanas laiks;
Ir dotas relācijas starp tabulām:
- viens-pret-daudziem relācija starp tabulām skoleni un vertejumi (vienam skolēnam var būt vairāki vērtējumi);
- viens-pret-daudziem relācija starp tabulām prieksmeti un vertejumi (vienam mācību priekšmetam var būt vairāki vērtējumi no dažādiem skolēniem).
Piemērs - hokejistu turnīru statistikas datubāze
Ir izveidota datubāze, kura uztur informāciju par hokejistu turnīru statistiku.
Katram spēlētājam tiek uzskaitīti punkti par gūtajiem vārtiem un rezultatīvām piespēlēm.
Statistiku krāj par katru spēli. Statistikā tiek iekļauta informāciju par spēlētāju, komandu, pretinieku, spēles datumu un vietu.
Dots ER modelis.
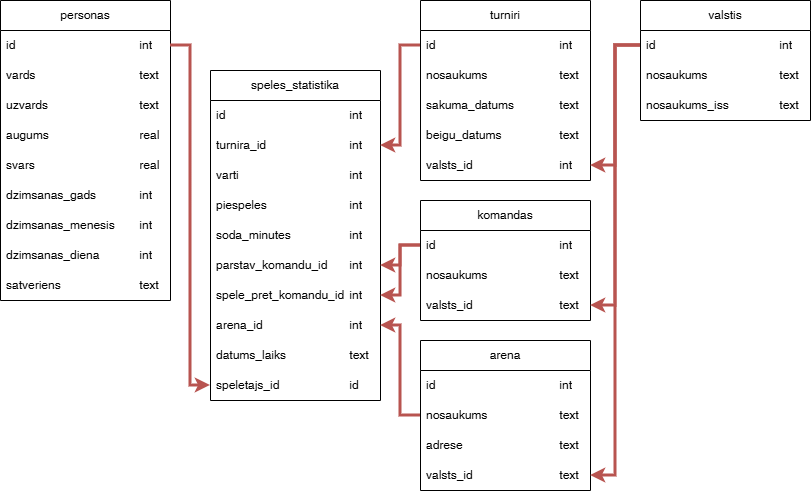
Galvenā tabula, kura visu informāciju uzglabā, ir tabula speles_statistika.
Šai tabulai tiek piesaistītas pārējās tabulas.
Pēc šī zīmējuma var secināt, ka spēlētājs var spēlēt vairākās komandās viena turnīra laikā, kas nav īsti reāli, bet šis ir tikai piemērs datubāzes relāciju zīmēšanai.
Tabulu apraksti:
personas tabulā ir lauki:
id(primārā atslēga);vards- spēlētāja vārds;uzvards- spēlētāja uzvārds;svars- spēlētāja svars;augums- spēlētāja augums;dzimsanas_gads- spēlētāja dzimšanas datuma gads;dzimsanas_menesis- spēlētāja dzimšanas datuma mēnesis;dzimsanas_diena- spēlētāja dzimšanas datuma diena;satveriens- spēlētāja satveriens (kreisais/labais);
speles_statistika tabulā ir lauki:
id(primārā atslēga);turnira_id- turnīra identifikators;varti- vārti gūti spēlē;piespeles- rezultatīvas piespēles spēlē;soda_minutes- soda minūtes spēlē;parstav_komandu_id- komanda, kuru pārstāv spēlētājs;spele_pret_komandu_id- komanda, pret kuru spēlē;arena_id- arēna, kurā notiek spēle;datums_laiks- spēles datums un laiks;speletajs_id- spēlētājs, kurš piedalās spēlē;
turniri tabulā ir lauki:
id(primārā atslēga);nosaukums- turnīra nosaukums;sakuma_datums- turnīra sākuma datums;beigu_datums- turnīra beigu datums;valsts_id- turnīra bāzes valsts identifikators;
komandas tabulā ir lauki:
id(primārā atslēga);nosaukums- komandas nosaukums;valsts_id- komandas valsts identifikators;
arena tabulā ir lauki:
id(primārā atslēga);nosaukums- arēnas nosaukums;adrese- arēnas adrese;valsts_id- arēnas valsts identifikators;
valstis tabulā ir lauki:
id(primārā atslēga);nosaukums- valsts nosaukums;nosaukums_iss- valsts īsais nosaukums (2 burti);
Šajā datubāzē ir šādas relācijas starp tabulām:
- viens-pret-daudziem relācija starp tabulām personas (
id) un speles_statistika (speletajs_id) (vienam spēlētājam var būt vairāki statistikas ieraksti); - viens-pret-daudziem relācija starp tabulām komandas (
id) un speles_statistika (parstav_komandu_id) (vienai komandai var būt vairāki statistikas ieraksti); - viens-pret-daudziem relācija starp tabulām komandas (
id) un speles_statistika (spele_pret_komandu_id) (vienai komandai var būt vairāki statistikas ieraksti); - viens-pret-daudziem relācija starp tabulām turniri (
id) un speles_statistika (turnira_id) (vienam turnīram var būt vairāki statistikas ieraksti); - viens-pret-daudziem relācija starp tabulām arena (
id) un speles_statistika (arena_id) (vienai arēnai var būt vairāki statistikas ieraksti); - viens-pret-daudziem relācija starp tabulām valstis (
id) un turniri (valsts_id) (vienai valstij var būt vairāki turnīri); - viens-pret-daudziem relācija starp tabulām valstis (
id) un komandas (valsts_id) (vienai valstij var būt vairāki turnīri); - viens-pret-daudziem relācija starp tabulām valstis (
id) un arena (valsts_id) (vienai valstij var būt vairāki turnīri);
ER modeļus zīmēt ērti ir vietnē draw.io
Indeksi
Īsumā: SQL indeksi ne tikai paātrina DB lasīšanas ātrumu, bet arī samazina lasītās rindas.
SQL indeksi ir kā nelielas atsevišķas tabulas datubāzē, kurās tiek glabātas norādes uz datu rindām tabulā. Indeksi ļauj datubāzei ātri atrast konkrētus datus un rindas, nemeklējot visus tos tabulā. Tas krietni uzlabo vaicājumu veiktspēju.
Salīdzinājumā ar īsto dzīvi mēs varam ņemt satura rādītāju grāmatā. Tā vietā, lai šķirstītu katru lapu grāmatā meklējot konkrētu tematu, jūs varat apskatīties saturā kur tas temats atrodas un uzreiz pāriet uz saturā norādīto lapu. Līdzīgi, indeksi datubāzei parāda kur tieši atrodas meklējamās datu rindas.
Viens mīnuss ar indeksiem ir tas, ka tas palielina atmiņas izmaksas datubāzei un var nedaudz palēlināt datu modifikācijas operācijas kā INSERT, UPDATE un DELETE.
Tā lai būtu vienkāršāk saprast kur vajag pielietot indeksus, mēs apskatīsim piemēru no īstās dzīves, ar kuru jūs visticamāk sadursities, ja strādāsiet ar datu bāzēm.
Problēma
Datubāzē ir 500 000 rindas ar cilvēkiem un jūs vēlaties izvēlēties cilvēkus kuriem dzimšanas diena ir starp 1988-01-01 un 1988-01-31.
Ja mēs strukturējam SQL vaicājumu šādi:
SELECT * FROM people WHERE birthday BETWEEN '1988-01-01' AND '1988-01-31';... tad datubāze iziet cauri VISĀM 500 000 rindām, bet atdod tikai 1378 rindas.
Ja ir maza datubāze un maz lietotāju, tad tā nav pārāk liela problēma, BET ja tev, piemēram, ir 500 000 rindas tabulā un katrs vaicājums iziet caur visām tām rindām, tad kopējais lasītais rindu skaits ļoti ātri pieaug (ļoti labs piemērs par to, kas var notikt šādos apstākļos). Tas var ne tikai ietekmēt datu bāzes veiktspēju, bet arī palielināt izmaksas, ja izmantojat datu bāžu pakalpojumus.
Pirms mēs kaut ko sākam risināt, mums vajadzētu sākumā saprast kas tiešām ar vaicājumu notiek izmantojot Explain komandu.
Risinājums
Ja mēs vaicājumu visu laiku filtrējam pēc vienas kolonas (piem. dzimšanas dienas), tad to kolonu mēs varam padarīt par indeksu.
-- MySQL sintakse
ALTER TABLE people ADD INDEX (birthday);
-- SQL sintakse
ALTER TABLE people CREATE INDEX (birthday);Tas krietni palielinās veiktspēju un samazinās lasīto rindu skaitu.
Mēs varam noteikt vai tas tiešām ir samazinājis lasīto rindu skaitu ar Explain komandu
Aptverošais indekss
Svarīgi!
Šī sadaļa ir galvenokārt priekš MySQL
Šo indeksu vajag izmantot tikai retajos gadījumos, kad ir nemainīgs vaicājums kuram vajag pēc iespējas mazāku izpildīšanas laiku. Šo indeksu vajag pievienot projekta izstrādes laika beigās, kad projekts ir pabeigts un ir jāveic optimizācija. Netaisi projektu ap šo stratēģiju.
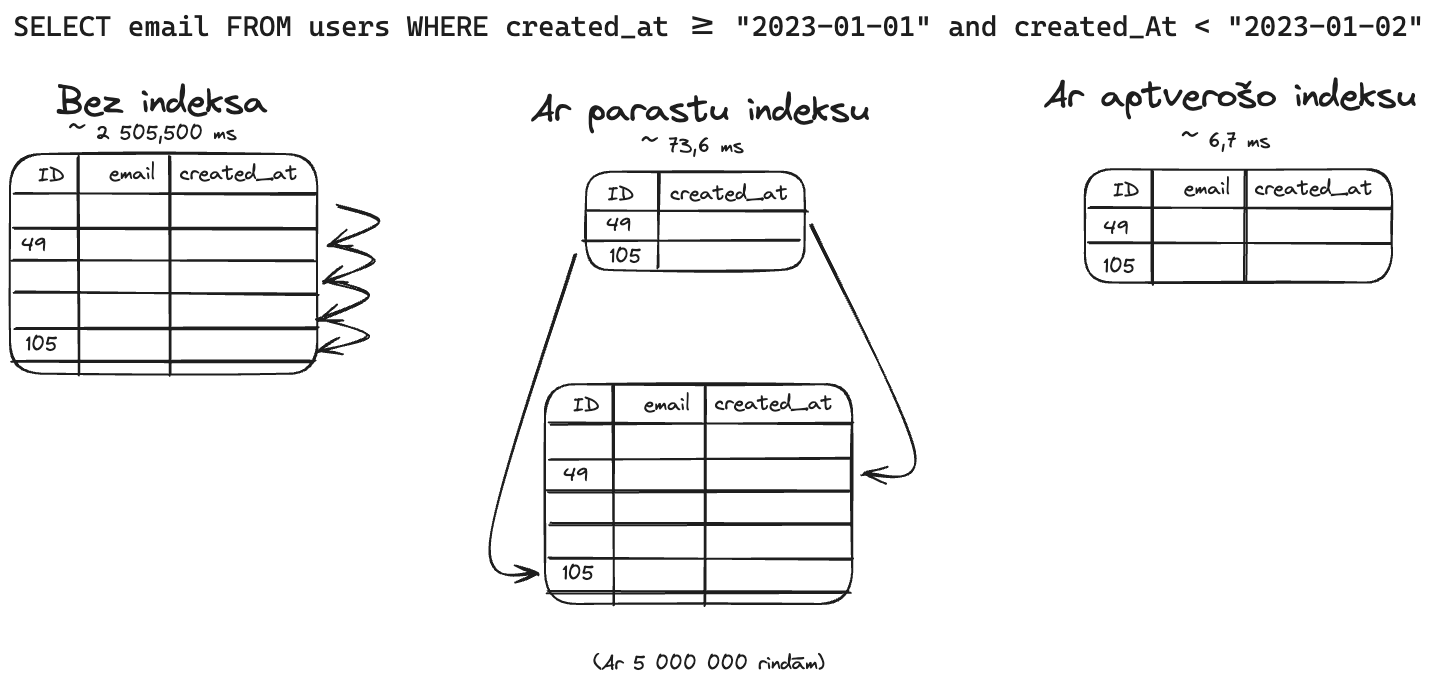
Ja mums vajag paņemt kolonas vērtību ar filtru (piem. created_at) un mums ir liela datu bāze (piem. 5 milj. rindas) tad mēs varam neizmantot indeksu, vai arī izmantot vienu no diviem indeksu veidiem.
SELECT email FROM users WHERE created_at >= "2023-01-01" and created_At < "2023-01-02"- Bez indeksa (~ 2 505,500 ms)
- Ar indeksu
created_at(~73,6 ms) - Ar aptverošo indeksu (~ 6,7 ms)
Kā mēs redzam, aptverošais indekss ir daudz ātrāks par parastu indeksu, bet kas tas īsti ir, un kā mēs to varam pielietot?
Aptverošais indekss ir ļoti specifisks indekss kurš aptver visus datus kurus gribat atgriezt UN pēc kā jūs filtrējat.
Parasts indekss būtu uz kolonas created_at. Tā būtu loģiskākā vieta balstoties uz iepriekšējo info, bet kas notiktu ja mēs uztaisītu vienu indeksu priekš 2 kolonām?
Lai uztaisītu Covering indeksu mēs uztaisām vienu indeksu ar 2 kolonām pēc SQL vaicājumu izpildes secības:
- Filtra kolona
- Kolonu, kuras datus gribi izvēlēties
Šajā piemērā tas izskatītos šādi:
ALTER TABLE users ADD INDEX created_at_email(created_at, email)Uztaisot šāda veida indeksu mēs varam izdarīt tā, lai tas vaicājums nekad nepieskaras pašai tabulai. Tas tikai paņem datus no ātrā un optimizētā indeksa.
Mēs varam pārliecināties vai aptverošais indekss strādā ar Explain komandu.

Pirmā vieta kur mums ir jāskatās ir Extra kolona. Tas izskaidro ko datu bāze izmanto, lai dabūtu datus. Ja tur ir Using index beigās, tad tas nozīmē ka datu bāze izmanto aptverošo indeksu un galīgi nepieskaras tabulai.
Tad, ja skatoties uz key kolonu ir aptverošā indeksa vārds, tad viss ir labi un tieši tas vaicājums būs ļoti ātrs.
Ja mēs izmantojam aptverošo indeksu, tad ir jāpārliecinās, ka tie dati kurus jūs vēlaties paņemt un tie dati kuri ir indeksā sakrīt. Jeb, ka ja mēs uztaisām indeksu ar (created_at, email), tad mums ir jāliek tikai tās divas kolonas vaicājumā.
Ja mēs ņemam * vai kādu citu vērtību, tad datu bāze turpina tā it kā tas aptverošais indekss nepastāvētu.
Izmantojot Explain komandu mēs varam pārliecināties vai vaicājums izmanto aptverošo indeksu pēc Extra un key kolonām.
Šajā piemērā (SELECT * [...]) mēs varam redzēt, ka aptverošais indekss netiek izmantots pēc atslēgas vārdiem Using MRR. Kā arī mēs varam redzēt ka tomēr kaut kāds indekss tiek izmantots, bet tas ir parastais un nevis aptverošais indekss, tāpēc šajā gadījumā šis vaicājums būs ~73,6 ms nevis ~6,7ms.
Ja mēs ņemam SELECT email, id [...] vai pat SELECT id [...] tad Using index vajadzētu pazust, jo tas nav indeksā... bet tā nenotiek.
Kāpēc? Jo id ir primārā atslēga, un primārā atslēga ir ielikta visos indeksos. Jeb, ka kad mēs uztaisījām aptverošo indeksu priekš (created_at, email), mēs īstenībā uztaisījām indeksu priekš (created_at, email, id).
SQLite
SQLite ir atvieglots SQL paveids, jo datu bāzei nav nepieciešams serveris un tā var glabāties datnē ar paplašinājumu .sqlite vai .db.
SQLite ir iebūvēta kā Python bibliotēka, tāpēc to var izmantot bez papildus instalācijas.
SQLite ir vienkārša un ātra, bet tai ir ierobežotas iespējas salīdzinot ar MySQL vai PostgreSQL.
SQLite datu bāze ir piemērota maziem projektiem, jo tā var glabāt tikai vienu lietotāju vienlaicīgi.
Tas rada zināmus drošības riskus, bet atvieglo datu bāzes izstrādi un testēšanu.
Lai darbotos ar SQLite un līdzīgām datu bāzēm, jāzina dažas svarīgākās komandas.
CREATE TABLE preces;
-- veido tabulu ar doto nosaukumu
DROP TABLE preces;
-- dzēš tabulu ar doto nosaukumu un datus no tās
INSERT INTO preces (nosaukums, cena, daudzums) VALUES ("Persiks", 0.40, 3);
-- ievieto tabulā jaunu ierakstu ar dotajām vērtībām
SELECT * FROM preces WHERE cena > 1.20;
-- atlasa preces, kurām cena lielāka par 1.20; izvada visus laukus
SELECT nosaukums FROM preces WHERE nosaukums LIKE 'Z%';
-- atlasa preces, kurām nosaukums sākas ar Z; izvada tikai nosaukumus
SELECT * FROM preces ORDER BY cena DESC LIMIT 5;
-- atlasa 5 dārgākās preces, izvada visus laukus
DELETE FROM preces WHERE daudzums = 0;
-- dzēš no tabulas tās preces, kurām daudzums ir 0Komandu var rakstīt vairākās rindās, bet tās beigās vienmēr jālieto semikols!
Lai redzētu lietotājam ērtā veidā SQLite datubāzi, viens no risinājumiem ir izmantot DB Browser for SQLite.
Vizuālā saskarne izskatās šādi:
Avots: https://sqlitebrowser.org/
SQLite datu tipi
SQLite datu tipi ir līdzīgi citu SQL datu bāzu tipiem, bet ir dažas atšķirības.
| Datu tips | Apraksts | Piemērs |
|---|---|---|
| INTEGER | Vesels skaitlis | 4 |
| REAL | Decimālskaitlis | 5.6 |
| TEXT | Teksts | Anna |
| DATE | Datums | 2023-01-01 |
| NULL | Tukšā vērtība | NULL |
Datubāzes izveide
Lai uzsāktu veidot SQLite datubāzi, jāver vaļā DB Browser for SQLite un jāizveido jauna datubāze.
Tālāk izvēlamies kur to saglabāt un kā to nosaukt.
Pēc tam mēs varam sākt veidot tabulas un ievietot datus.
Veidosim tabulu ar nosaukumu personas.
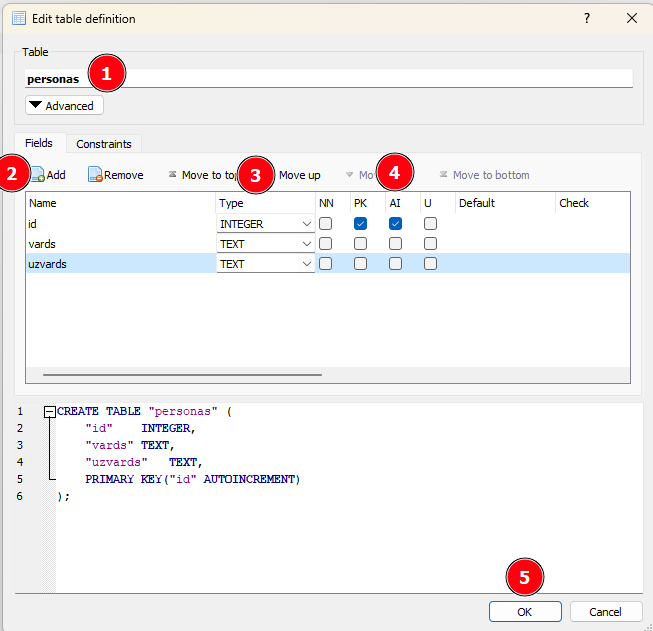
Numuri un to darbības
| Numurs | Darbība |
|---|---|
| 1. | Ieraksta datubāzes tabulas nosaukumu |
| 2. | Ieraksta kolonas nosaukumu |
| 3. | Ieraksta kolonas datu tipu |
| 4. | Ja tā ir identifikatora kolona, tad izvēlas AI* |
| 5. | Ja tā ir primārā atslēga, tad izvēlas PK |
*AI - Autoincrement, lai katrs ieraksts dabūtu unikālu ID un tas automātiski palielinātos.
Tāpat arī apakšējā logā ir redzams SQL vaicājums, kas tiks izpildīts, kad tiks spiests OK.
To vēl iespējams koriģēt, ja nepieciešams.
Pēc tam mēs varam ievietot datus. Lai atrastu datubāzes tabulu, spiežam uz Database Structure un tad uz Browse Data.
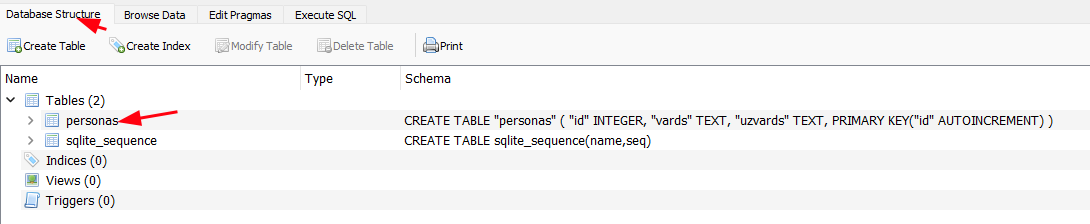
Pēc tam mēs varam ievietot datus.
Spiež uz Browse Data un tad uz New Record.
Divvreiz uzspiežot uz kolonas, var ievadīt jaunus datus.
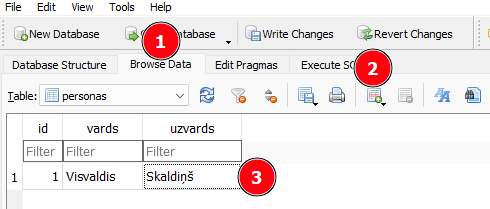
Kad jaunie dati ir ievadīti, tad spiež Write Changes, lai saglabātu tos.
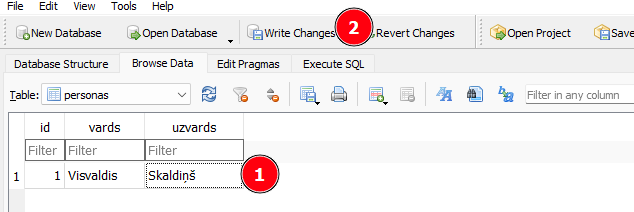
Pēc tam mēs varam veikt vaicājumus no Python puses.
Ja vēlamies pārbaudīt SQL vaicājumus, tad to dara cilnē Execute SQL.Excute SQL ļauj veikt vaicājumus un redzēt rezultātus, iespējams arī redzēt kļūdas un labot datus.
Python un SQLite
Imports un savienojums
Lai darbotos ar SQLite no Python, mums ir jāimportē sqlite3 bibliotēka.
import sqlite3Lai izveidotu savienojumu ar datubāzi, mums ir jāizveido connection objekts. To sāisinām un rakstām con.
Tiek pievienots arī cursor objekts, lai veiktu vaicājumus. To sāisinām un rakstām cur.
Kursors ir kā rādītājs uz rindu datubāzē. Tas ļauj mums pārvietoties pa rindām un veikt darbības ar tām - lasīt, rakstīt datus utt.
import sqlite3
con = sqlite3.connect("datubaaze.db")
cur = con.cursor()Datu nolasīšana
Tagad varam veikt darbības ar datubāzi. Nolasīsim visu personu datubāzi.
import sqlite3
con = sqlite3.connect("datubaaze.db")
cur = con.cursor()
dati = cur.execute("SELECT * FROM personas")
for rinda in dati:
print(rinda[1])
con.close()Mainīgais dati satur visus ierakstus no personas tabulas, mēs šo secību izveidojām, būvējot tabulu.for cikls iziet cauri visiem ierakstiem un izvada katras rindas otrās kolonas vērtību.con.close() aizver savienojumu ar datubāzi.
Svarīgi!
Datubāzes kolonas ir šādas secībā: id, vārds, uzvārds.
Tāpat kā ar sarakstiem, arī SQLite un Python lasīšanā indeksācija sākas no 0.
Tas ir specifiski SQLite datubāzei un Python veidam kā to nolasīt.
Svarīgi!
Ir iespējams datus nolasīt ar vārdnīcas atslēgu, nevis ar indeksu.
Lai to izdarītu, ir jāiestata row_factory uz sqlite3.Row pirms kursora izveides.
Kvadrātiekavās rakstām kolonas nosaukumu, lai nolasītu datus.
import sqlite3
con = sqlite3.connect("datubaaze.db")
con.row_factory = sqlite3.Row
cur = con.cursor()
dati = cur.execute("SELECT * FROM personas")
for rinda in dati:
print(rinda["vards"])
con.close()Datu ievietošana
Pievienosim jaunu ierakstu datubāzes tabulā personas.
Personas vārds un uzvārds ir Jānis Bērziņš.
import sqlite3
con = sqlite3.connect("datubaaze.db")
cur = con.cursor()
cur.execute("INSERT INTO personas (vards, uzvards) VALUES ('Jānis', 'Bērziņš')")
con.commit()
con.close()Šajā piemērā mēs izmantojam execute metodi, lai izpildītu SQL vaicājumu.INSERT INTO personas (vards, uzvards) VALUES ('Jānis', 'Bērziņš') ievieto jaunu ierakstu tabulā personas ar vārdu Jānis un uzvārdu Bērziņš.
Svarīgi, ka šajā piemērā mēs izmantojam con.commit(), lai saglabātu izmaiņas datubāzē.
Pretējā gadījumā izmaiņas netiks saglabātas.
Ja mums ir nepieciešams ielādēt datus no mainīgajiem un nevis statiskā tekstā, tad mēs varam izmantot ? zīmi un kortežu ar vajadzīgajām vērtībām.
Info
Tuple latviskais tulkojums ir kortežs. Tā ir vērtību grupa, kura ir nemainīga.
Līdzīgi kā saraksts, bet ar nemainīgiem elementiem.
import sqlite3
con = sqlite3.connect("datubaaze.db")
cur = con.cursor()
vards = "Jānis"
uzvards = "Bērziņš"
cur.execute("INSERT INTO personas (vards, uzvards) VALUES (?, ?)", (vards, uzvards))
con.commit()
con.close()Jautājuma zīmes apzīmē mainīgos, kas tiks ievietoti datubāzē. Tuple ar mainīgajiem tiek padots kā otra arguments execute metodei.
Manīgie tiek likti tādā pašā secībā, kādā tie ir tabulā.
Secību nosaka daļa SQL vaicājumā INTO personas (vards, uzvards), kur vārds ir pirmā jautājuma zīme, bet uzvārds ir otrā.
Ja tagad mēs gribētu redzēt visas personas, kuras ir ievietotas datubāzē, tad mēs varētu izmantot iepriekšējo piemēru.
Otrs veids kā ievadīt vērtības ir no ievades lauciņa, kuru aizpilda lietotājs.
import sqlite3
con = sqlite3.connect("datubaaze.db")
cur = con.cursor()
vards = input("Ievadiet vārdu: ")
uzvards = input("Ievadiet uzvārdu: ")
cur.execute("INSERT INTO personas (vards, uzvards) VALUES (?, ?)", (vards, uzvards))
con.commit()
con.close()Šajā piemērā lietotājs ievada vārdu un uzvārdu, un šīs vērtības tiek ievietotas datubāzē.
Ja vēlamies nolasīt datus no datubāzes, tad mēs varam izmantot SELECT vaicājumu.
Piemērā mēs atlasām visus vārdus no personas tabulas. Šie dati jau pievienoti iepriekš.
import sqlite3
con = sqlite3.connect("datubaaze.db")
cur = con.cursor()
dati = cur.execute("SELECT * FROM personas")
for rinda in dati:
print(rinda[1])
con.close()Visvaldis
JānisDatu dzēšana
Ja mēs gribam izdzēst ierakstu no datubāzes, tad mēs varam izmantot DELETE vaicājumu.
import sqlite3
con = sqlite3.connect("datubaaze.db")
cur = con.cursor()
cur.execute("DELETE FROM personas WHERE vards = 'Jānis'")
con.commit()
con.close()Tiek izdzēstas visas personas ar vārdu Jānis.
Dinamiskā meklēšana pēc lietotāja ievades ir iespējama, izmantojot ? zīmi un tuple. Šajā gadījumā mēs gribētu meklēt to ko ievadījis lietotājs.
import sqlite3
con = sqlite3.connect("datubaaze.db")
cur = con.cursor()
ievade = input("Ievadiet vārdu: ")
cur.execute("SELECT * FROM personas WHERE vards = ?", (ievade))
dati = cur.fetchall()
for rinda in dati:
print(rinda[1])
con.close()Šajā piemērā tiek atlasītas visas personas ar vārdu, ko ievada lietotājs.input funkcija ļauj lietotājam ievadīt datus.cur.fetchall() atgriež visas rindas, kas atbilst meklēšanas kritērijam.for cikls izvada visas personas ar ievadīto vārdu.
Pēdējais ievietotais ID
Ir gadījumi, ka nepieciešams iegūt rindas identifikatoru pēc tam, kad ir ievietots jauns ieraksts datubāzē.
import sqlite3
con = sqlite3.connect("datubaaze.db")
con.row_factory = sqlite3.Row
cur = con.cursor()
vards = "Jānis"
uzvards = "Bērziņš"
cur.execute("INSERT INTO personas (vards, uzvards) VALUES (?, ?)", (vards, uzvards))
con.commit()
last_id = cur.lastrowid
print(f"Ievietotā ieraksta ID ir: {last_id}")Šo var izmantot, ja nepieciešams saglabāt relācijas starp tabulām.
Temperatūras uzskaites datubāzes piemērs ar SQLite
Ir izveidota vienkārša datubāze, kura reģistrē temperatūras vērtības ar laika atzīmi.
Šo programmu var izmantot, lai simulētu temperatūras reģistrēšanu ik pēc sekundes.
Programmu var pielāgot, lai reģistrētu temperatūras vērtības no sensora vai cita avota.
# Imports
import sqlite3
#Lai iegūtu laiku un nejaušas vērtības
import time
import random
import datetime
# Savienojums ar datubāzi
con = sqlite3.connect("datubaze.db")
con.row_factory = sqlite3.Row
cur = con.cursor()
# Skaitītājs ciklam
skaititajs = 0
# Galvenais cikls
while True:
# Te jāievieto kods, kas iegūst temperatūras vērtību no sensora vai cita avota
# Šajā piemērā tiek ģenerēta nejauša vērtība no -20 līdz 20
temperaturas_vertiba = random.randint(-20,20)
# Iegūst pašreizējo laiku
laiks = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
# Ievieto datus datubāzē
cur.execute("insert into registracija (vertiba,laiks) values (?,?)",(temperaturas_vertiba,laiks,))
con.commit()
# Izvada reģistrēto vērtību un laiku
print(f'Reģistrācijas laiks {laiks} un vērtība {temperaturas_vertiba} ')
# Katru 10 reizi aprēķina un izvada vidējo temperatūru
if skaititajs == 10:
# Visa laika vidējā temperatūra
vaicajums = cur.execute("SELECT AVG(vertiba) as videjie_gradi FROM registracija")
dati = vaicajums.fetchone()
print(f"Visa laika vidējā temperatūra {round(dati['videjie_gradi'],2)} grādi.")
# Pēdējās stundas vidējā temperatūra
vaicajums = cur.execute("SELECT AVG(vertiba) as videjie_gradi_menesis FROM registracija WHERE laiks >= datetime('now', '-1 hour')")
dati = vaicajums.fetchone()
print(f"Pēdējās stundas vidējā temperatūra {round(dati['videjie_gradi_menesis'],2)} grādi.")
# Notīra skaitītāju
skaititajs = 0
else:
# Paaugstina skaitītāju par 1
skaititajs += 1
# Gaida 1 sekundi līdz nākamajai reģistrācijai
time.sleep(1)Datubāzes tabulas izveides SQL komanda izskatās šādi:
CREATE TABLE "registracija" (
"id" INTEGER,
"vertiba" REAL,
"laiks" REAL,
PRIMARY KEY("id" AUTOINCREMENT)
);ST_distance_sphere
Ja mums ir 2 ģēogrāfiski punkti ar ģeogrāfiskajiem platumiem un ģeogrāfiskajiem garumiem, un mēs vēlamies dabūt attālumu metros starp diviem punktiem, mums ir jaizmanto haversīna formula.
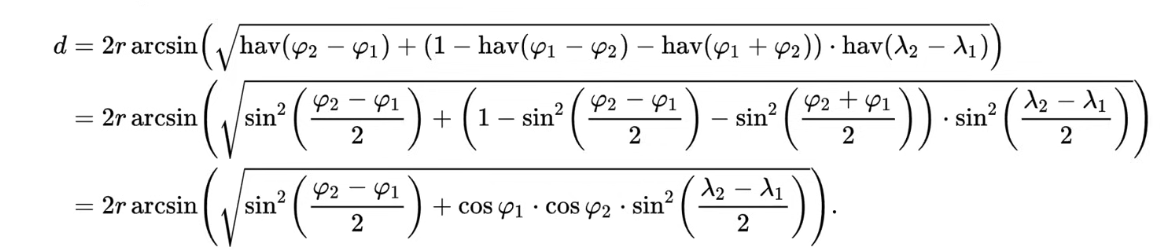
... bet tā formula ir ļoti sarežģīta un lai gan mēs varam viņu paši iekodēt, ir liela iespējamība, ka mēs pieļausim kļūdu, vai ka nebūs optimizēti. Tāpēc MySQL datubāze nāk ar iebūvētu komandu, kas to aprēķina.
select ST_distance_sphere(
point(garums, platums),
point(garums, platums)
-- papildus arguments - metri (riņķa platums). Pēc noklusējuma MySQL ņem zemeslodes platumu (6 370 986 m).
); -- atgriež attālumu metrosIzmantošana filtrā
Ja mēs vēlamies atlasīt visus ģeogrāfiskos punktus 1 km attālumā no centra punkta mēs varam izmantot ST_distance_sphere kā filtru.
SELECT
*
FROM
addresses
WHERE
ST_distance_sphere(
point(-1.234567, 2.345678), -- "Point Of Interest" (centra punkts)
point(longitude, latitude) -- longitude (ģeogrāfiskais garums) un latitude (ģeogrāfiskais platums) - kolonas tabulā
) < 1000 -- kur attālums ir mazāks par 1 kmŠī komanda ir samērā smaga, tāpēc ir ieteikts vismaz izmantot indeksus priekš ģeogrāfiskā garuma un platuma kolonām (lon(longitude), lat(latitude)).
Changelog
13ae5-on